As habilidades avançadas do ChatGPT, como debugar código, escrever um ensaio ou fazer uma piada, têm levado à sua enorme popularidade. Apesar de suas habilidades, sua assistência foi limitada ao texto - mas isso está prestes a mudar.
Na terça-feira, a OpenAI revelou o GPT-4, um grande modelo multimodal que aceita tanto textos quanto imagens como entrada e gera texto como saída.
Também: Como fazer o ChatGPT fornecer fontes e citações
A distinção entre o GPT-3.5 e o GPT-4 será "sutil" em conversas informais. No entanto, o novo modelo será muito mais capaz em termos de confiabilidade, criatividade e até inteligência.
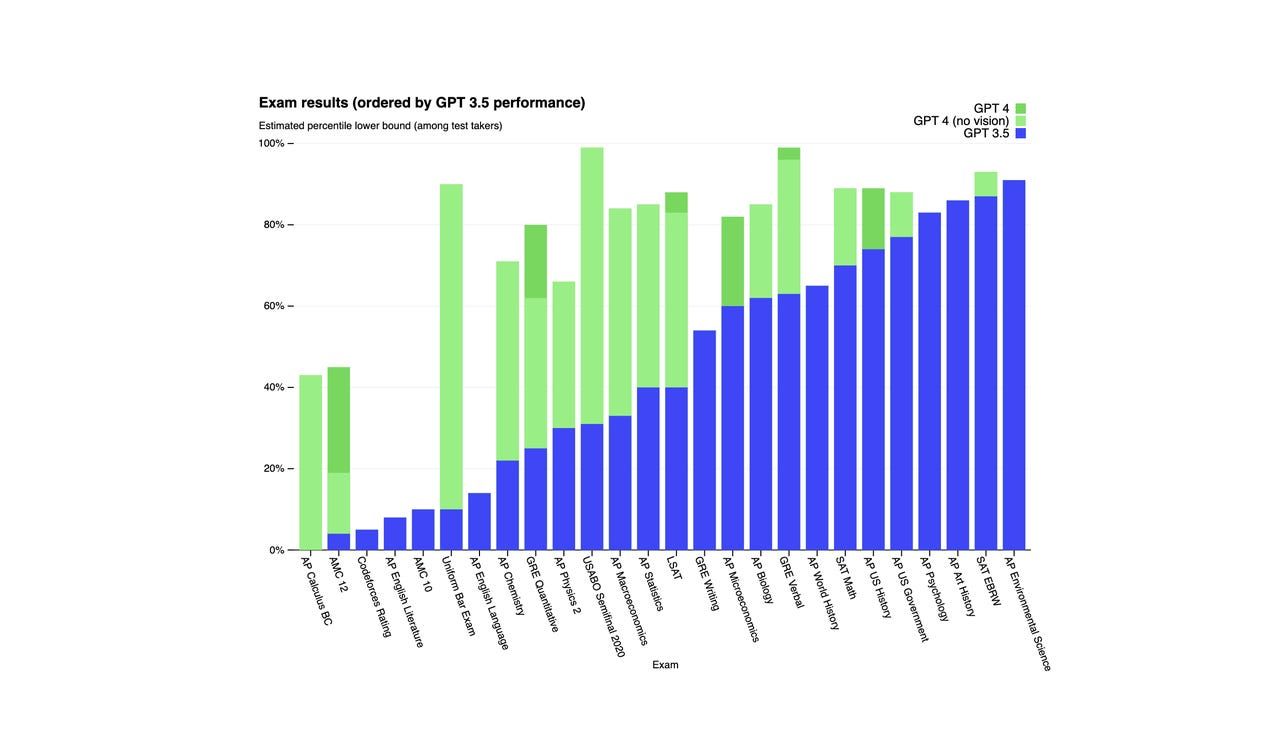
De acordo com a OpenAI, o GPT-4 obteve pontuação entre os 10% melhores em um exame simulado da ordem, enquanto o GPT-3.5 pontuou entre os 10% mais baixos. O GPT-4 também teve melhor desempenho que o GPT-3.5 em uma série de testes de referência, conforme mostrado no gráfico abaixo.

Para contextualizar, o ChatGPT é executado em um modelo de linguagem ajustado a partir de um modelo da série 3.5, o que limita o chatbot a gerar apenas texto.
O anúncio do GPT-4 da OpenAI seguiu um discurso de Andreas Braun, CTO da Microsoft Alemanha, na semana passada, no qual ele disse que o GPT-4 estaria chegando em breve e possibilitaria a geração de texto para vídeo.
Também: Como o ChatGPT funciona?
"Vamos apresentar o GPT-4 na próxima semana; lá teremos modelos multimodais que oferecerão possibilidades completamente diferentes -- por exemplo, vídeos," disse Braun, segundo a Heise, um portal de notícias alemão, no evento.
Apesar do GPT-4 ser multimodal, as alegações de um gerador de texto-para-vídeo estavam um pouco equivocadas. O modelo ainda não consegue produzir vídeos, mas consegue aceitar inputs visuais, o que representa uma mudança importante em relação ao modelo anterior.
Um dos exemplos fornecidos pela OpenAI para mostrar essa funcionalidade mostra o ChatGPT analisando uma imagem na tentativa de descobrir o que na foto é engraçado, de acordo com a entrada do usuário.
Outros exemplos incluíram fazer upload de uma imagem de um gráfico e pedir ao GPT-4 para fazer cálculos a partir dela, ou fazer upload de uma planilha e pedir para ele resolver as perguntas.
Também: 5 formas como o ChatGPT pode te ajudar a escrever um ensaio
A OpenAI anuncia que lançará a capacidade de entrada de texto do GPT-4 por meio do ChatGPT e sua API por meio de uma lista de espera. Você terá que esperar um pouco mais pelo recurso de entrada de imagem, pois a OpenAI está colaborando com um único parceiro para iniciar isso.
Se você está decepcionado por não ter um gerador de texto para vídeo, não se preocupe, não é um conceito completamente novo. Gigantes da tecnologia como Meta e Google já têm modelos em desenvolvimento. A Meta tem o Make-A-Video e o Google tem o Imagen Video, ambos utilizam IA para produzir vídeos a partir da entrada do usuário.